

1 上游与下游的定义
在微服务架构中,当服务A调用服务B时,会形成一个调用关系。这个关系中的方向决定了上游(Upstream)和下游(Downstream)的身份:
- 🎯 调用方(A服务)称为上游 – 它是请求的发起者,是调用链的起点
- 🎯 被调用方(B服务)称为下游 – 它是请求的处理者,是调用链的终点
这种命名方式反映了数据流的方向:数据从上游流向下游。举个例子,如果订单服务(Order Service)需要调用支付服务(Payment Service)来完成交易,那么在这个场景中:
- 订单服务是支付服务的上游(调用方)
- 支付服务是订单服务的下游(被调用方)
为了更清晰地理解这一关系,以下是微服务调用中上下游关系的可视化表示:
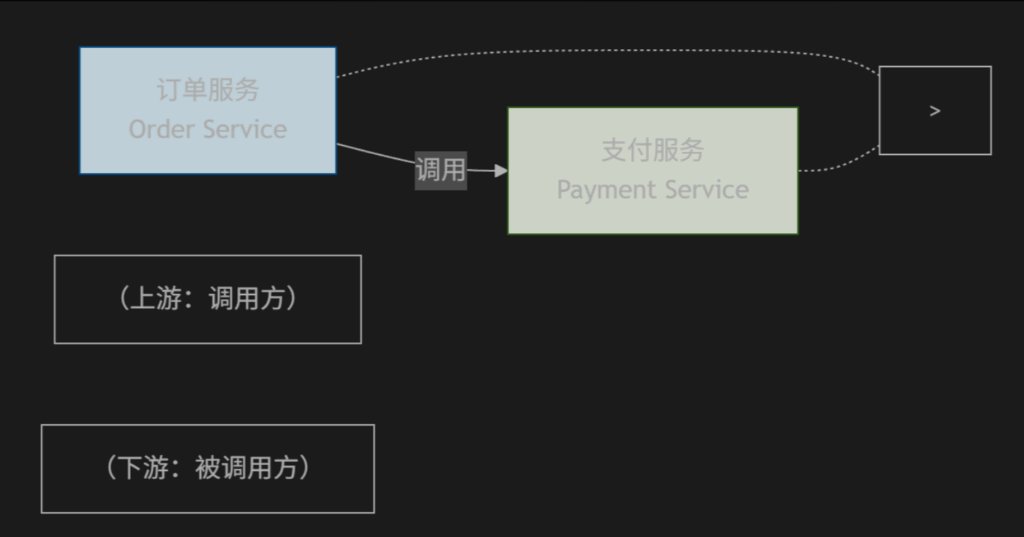
这种上下游关系是微服务架构中依赖关系的核心体现。上游服务依赖于下游服务的功能来完成自己的业务逻辑,而下游服务则向上游服务提供能力而非消费能力。
2 有人说的“被调用方是上游”是怎么回事?
确实,偶尔会听到“被调用方是上游”的说法,这种观点通常源于两种误解:
2.1 术语的翻译与语境差异
- 英文技术文献中的”Upstream”和”Downstream”概念在中文语境下可能被直译而不考虑具体场景
- 在开源项目贡献和数据流处理领域中,这些术语的方向性与微服务调用中存在差异
2.2 不同视角的分歧
有些人从依赖关系而非调用关系的角度理解:
- 被调用方(服务提供者)是基础,类似于河流的“上游源头”
- 调用方(服务消费者)依赖于这个源头,处于“下游”
虽然这种理解在某些语境下有一定逻辑,但在微服务架构的标准术语中,按照调用方向定义上下游是行业共识。
下表对比了不同场景下的术语使用差异:
| 场景 | 上游 | 下游 | 说明 |
|---|---|---|---|
| 微服务调用 | 调用方 | 被调用方 | 行业共识标准 |
| 数据流处理 | 数据源/生产者 | 数据接收方/消费者 | 如Kafka消息队列 |
| 开源贡献 | 原始项目 | 分支项目 | 补丁向上游提交 |
| 依赖关系 | 基础服务 | 依赖服务 | 从稳定性视角 |
3 一个生动的比喻
想象一条河流:
- 上游是河流的起源,水从这里开始流动
- 下游是河流的终点,水在这里汇集
在微服务调用中:
- 上游服务就像是请求的“起源”,它发起调用
- 下游服务就像是请求的“终点”,它处理请求并返回结果
数据流就像河水一样,从上游流向下游。
再拿外卖订单打个比方:
- 顾客(调用方)下单 → 上游
- 餐厅(被调用方)接单制作 → 下游
顾客主动发起请求(下单),餐厅提供餐饮服务(响应请求)。如果没有顾客下单,餐厅就不会制作餐品。同样,在微服务调用中,没有上游的调用,下游就不会被触发处理任何请求。
4 微服务中的示例
让我们看一个微服务架构中的具体示例。假设我们有一个电子商务系统,包含多个服务:
- 订单服务 (Order Service):处理订单创建和查询
- 支付服务 (Payment Service):处理支付流程
- 库存服务 (Inventory Service):管理商品库存
- 用户服务 (User Service):管理用户信息
当用户下单时,订单服务需要调用支付服务、库存服务和用户服务。以下是这些服务之间的调用关系:
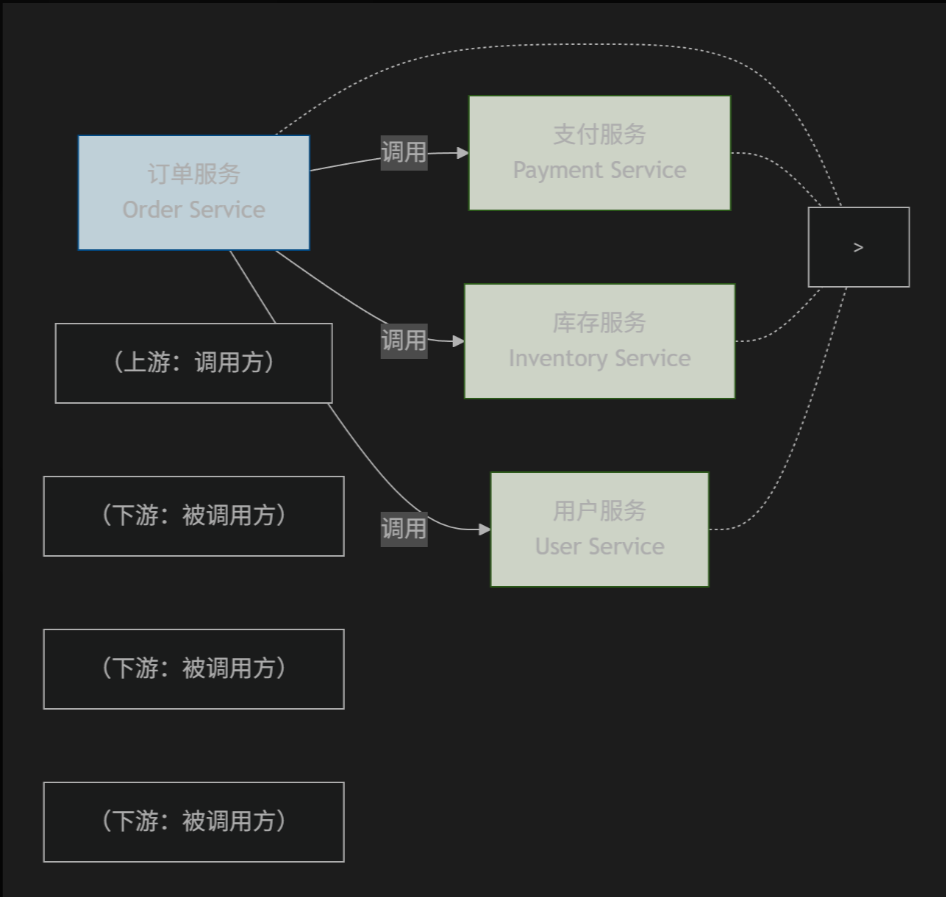
从图中可以看出,订单服务是支付服务、库存服务和用户服务的上游(调用方),而这些被调用的服务则是下游(被调用方)。
在实际代码中,这种调用关系可能看起来像这样(以订单服务调用支付服务为例):
// 在订单服务 (上游) 中
public class OrderService {
// 通过HTTP客户端调用支付服务
@Autowired
private RestTemplate restTemplate;
public void processPayment(String orderId, double amount) {
// 构造支付请求
PaymentRequest request = new PaymentRequest(orderId, amount);
// 调用支付服务 (下游)
ResponseEntity<PaymentResponse> response = restTemplate.postForEntity(
"http://payment-service/payments",
request,
PaymentResponse.class
);
// 处理响应
// ...
}
}同时,支付服务作为下游,会提供相应的API端点:
// 在支付服务 (下游) 中
@RestController
@RequestMapping("/payments")
public class PaymentController {
@PostMapping
public PaymentResponse processPayment(@RequestBody PaymentRequest request) {
// 处理支付逻辑
// ...
return new PaymentResponse("SUCCESS", "Payment processed");
}
}理解这种上下游关系对于设计微服务间的容错机制至关重要。例如,作为上游的订单服务需要考虑到下游服务可能失败或超时,并实施相应的重试机制、熔断策略(如使用断路器模式)和降级方案,从而提高系统的整体韧性。
5 为什么重要?
理解正确的上下游关系对于微服务架构的设计和运维至关重要,原因包括:
5.1 系统设计与依赖管理
- 清晰的依赖流向:帮助架构师理清服务之间的依赖关系,避免循环依赖
- 合理的拆分边界:指导微服务的合理拆分,确保单一职责原则
- 依赖稳定性:下游服务的稳定性直接影响上游服务,设计时需要考虑下游容错
5.2 问题排查与链路追踪
当系统出现问题时,正确的上下游概念帮助快速定位问题:
- 下游服务异常会直接影响上游服务
- 分布式追踪系统(如Zipkin、SkyWalking)使用上下游概念绘制调用图谱
- 监控指标(如延迟、错误率)需要沿着调用链从上游传播到下游
5.3 服务治理与流量控制
- 限流策略:下游服务需要对上游调用实施限流,防止被过量请求打垮
- 熔断机制:上游服务需要在检测到下游频繁失败时启动熔断,避免故障扩散
- 重试策略:上游服务可以针对下游的临时故障实施智能重试策略
总结
在微服务架构中,上游和下游的关系由调用方向决定:调用方是上游,被调用方是下游。这种区分不是学术上的吹毛求疵,而是理解服务间依赖关系、设计稳健的分布式系统的基石。
记住这个核心原则:
- 上游 → 调用方 → 请求发起者
- 下游 → 被调用方 → 服务提供者
无论是处理服务超时、实施熔断机制,还是进行性能优化,清晰理解上下游关系都能帮助您做出更明智的架构决策。在微服务的世界中,数据流动如同河流,只有理解其流向,才能更好地驾驭它。